
Product Data with cURL AND JSON
For this guide, we're going to assume the following you're interested in using Datafiniti's product data to analyze trends in the women's luxury shoe market. Let's say you're a data scientist that's been tasked with the following:
- Collect pricing data on women's luxury shoes from multiple online retailers.
- Sort the data by brand.
- Determine the average price of each brand.
Your environment and data needs:
- You're working with cURL.
- You want to work with JSON data.
Here are the steps we'll take:
1. Open your terminal
If you want to use cURL to access the Datafiniti API, we're assuming you have access to a standard, Linux-based terminal. Open a terminal session to get started.
2. Get your API token
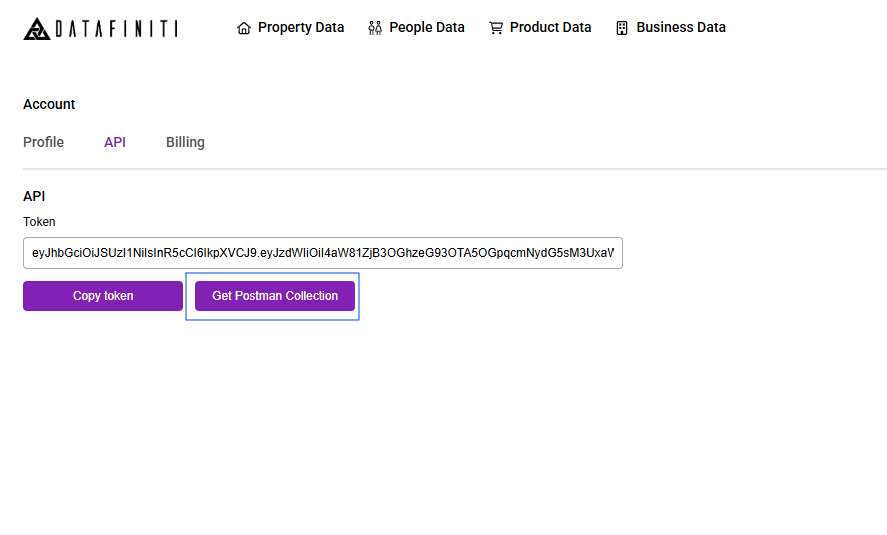
The next thing you'll need is your API token. The API token lets you authenticate with Datafiniti API and tells it who you are, what you have access to, and so on. Without it, you can't use the API.
To get your API token, go the Datafiniti Web Portal (https://portal.datafiniti.co), login, and click your settings in the left navigation bar. From there, you'll see a page showing your token. Your API token will be a long string of letters and numbers. Copy the API token or store it somewhere you can easily reference.
For security reasons, your API token will be automatically changed whenever you change your password.
API Key
For the rest of this document, we'll use
AAAXXXXXXXXXXXXas a substitute example for your actual API token when showing example API calls.
API Key Regen
For security reasons, your API token will be automatically changed whenever you change your password.
3. Run your first search
The first thing we'll do is do a test search that will give us a sense for what sort of data might be available. Eventually we'll refine our search so that we get back the most relevant data.
Since we want women's luxury shoes, let's try a simple search that will just give us listings for shoes sold online.
Enter the following into your terminal (replace the dummy API token with your real API token):
curl --request POST --url https://api.datafiniti.co/v4/products/search --header 'authorization: Bearer AAAXXXXXXXXXXXX' --data '{"query":"categories:shoes","num_records":1}'
You should get a response similar to this (although it may not look as pretty in your terminal):
{
"num_found": 884885,
"total_cost": 1,
"records": [
{
"asins": [
"B010XYTFM6"
],
"brand": "inktastic",
"categories": [
"Novelty",
"Tops & Tees",
"Novelty & More",
"Women",
"Clothing, Shoes & Jewelry",
"T-Shirts",
"Clothing"
],
"dateAdded": "2015-11-09T01:55:09Z",
"dateUpdated": "2016-04-12T16:19:26Z",
"imageURLs": [
"http://ecx.images-amazon.com/images/I/41W6xSgsBbL._SX342_QL70_.jpg",
"http://ecx.images-amazon.com/images/I/41StiamgorL._SR38,50_.jpg",
"http://ecx.images-amazon.com/images/I/41StiamgorL._SX342_QL70_.jpg",
"http://ecx.images-amazon.com/images/I/41W6xSgsBbL._SR38,50_.jpg"
],
"keys": [
"inktasticwomensbutterflybanjochickjuniorvnecktshirts/b010xytfm6"
],
"name": "Inktastic Women's Butterfly Banjo Chick Junior V-neck T-shirts",
"sourceURLs": [
"http://www.amazon.com/Inktastic-Womens-Butterfly-Junior-T-Shirts/dp/B010XYTK1W",
"http://www.amazon.com/Inktastic-Womens-Butterfly-Junior-T-Shirts/dp/B016HKYYN0",
"http://www.amazon.com/Inktastic-Butterfly-T-Shirts-Athletic-Heather/dp/B016HKYPYS"
],
"id": "AVkzMzokUmTPEltRlaJ_"
}
]
}
Let's break down what the API call is all about:
| API Call Component | Description |
|---|---|
"query": "categories:shoes" | query tells the API what query you want to use. In this case, you're telling the API you want to search by categories. Any product that has shoe listed in its categories field will be returned. |
"num_records": 1 | num_records tells the API how many records to return in its response. In this case, you just want to see 1 matching record. |
"format":"xxxx" | Format tells the API what format to output the data in the response. Can be either CSV or JSON |
Now let's dive through the response the API returned:
| Response Field | Description |
|---|---|
"num_found" | The total number of available records in the database that match your query. If you end up downloading the entire data set, this is how many records you'll use. |
"total_cost" | The number of credits this request has cost you. Product records only cost 1 credit per record. |
"records" | The first available matches to your query. If there are no matches, this field will be empty. Within each record returned, you'll see multiple fields shown. This is the data for each record. |
Within the records field, you'll see a single product returned with multiple fields and the values associated with that product. The JSON response will show all fields that have a value. It won't show any fields that don't have a value.
Each product record will have multiple fields associated with it. You can see a full list of available fields in our Product Data Schema.
4. Refine your search
If you take a look at the sample record shown above, you'll notice that it's not actually a pair of shoes. It's actually a shirt. It was returned as a match because its category keywords included Clothing, Shoes & Jewelry. If we downloaded all matching records, we would find several products that really are shoes, but we'd also find other products like this one, which aren't.
We'll need to refine our search to make sure we're only getting shoes. Modify your request body to look like this:
curl --request POST --url https://api.datafiniti.co/v4/products/search --header 'authorization: Bearer AAAXXXXXXXXXXXX' --data '{"query":"categories:shoes AND -categories:shirts AND categories:women AND (brand:* OR manufacturer:*) AND prices:*", "num_records": 10}'
This API call is different in a few ways:
- It uses
AND -categories:shirtsto filter out any products that might be shirts. Note the-in front ofcategories. - It adds
AND categories:womento narrow down results to just products for women. (We were interested in just women's shoes.) - It adds
AND (brand:* OR manufacturer:*). This ensures thebrandormanufacturerfield is filled out in all the records I request. We call the*a "wildcard" value. Matching against a wildcard is a useful way to ensure the fields you're searching aren't empty. - It adds
AND prices:*. Again, matching against a wildcard here means we're sure to only get products that have pricing information. - It changes
records=1torecords=10so we can look at more sample matches.
Notice how Datafiniti lets you construct very refined boolean queries. In the API call above, we're using a mix of AND and OR to get exactly what we want.
If you would like to narrow your search to just exact matches you can place the search term in quotation marks.
curl --request POST --url https://api.datafiniti.co/v4/products/search --header 'authorization: Bearer AAAXXXXXXXXXXXX' --data '{"query":"names:\"Apple Iphone 10\"", "num_records": 10}'
The above query will only return products with the exact name of Apple Iphone 10. The quotation marks need to be escaped using back slashes since they are already within another set of quotation marks.
5. Initiate a download of the data
Once we like what we see from the sample matches, it's time to download a larger data set! To do this, we're going to further modify our request to look like this:
curl --request POST --url https://api.datafiniti.co/v4/products/search --header 'authorization: Bearer AAAXXXXXXXXXXXX' --data '{"query":"categories:shoes AND -categories:shirts AND categories:women AND (brand:* OR manufacturer:*) AND prices:*", "num_records": 50, "download": true}'
Here's what we changed:
- We change
"num_records": 10to"num_records": 50. This will download the first 50 matching records. If we wanted to download all matching records, we would removenum_records.num_recordswill tell the API to default to all available records. - We added
"download": true. This tells the API to issue a download request instead of a search request.
If num_records is not specified, ALL of the records matching the query will be downloaded.
When you make this API call, you'll see a response similar to:
{
"id": 7,
"results": [],
"user_id": 15,
"status": "running",
"date_started": "2017-11-16 17:46:06.0",
"num_downloaded": 0,
"data_type": "product",
"query": "categories:shoes AND -categories:shirts AND categories:women AND (brand:* OR manufacturer:*) AND prices:*",
"format": "json",
"num_records": 50,
"total_cost": 50
}
We'll explain each of these fields in the next section.
When using the API, you will not receive any warning if you are going past your monthly record limit. Keep a track on how many records you have left by checking your account. You are responsible for any overage fees if you go past your monthly limit.
6. Monitor the status of the download
As the download request runs, you can check on its status by making a call to the /downloads/ endpoint like so:
curl --request GET --url https://api.datafiniti.co/v4/downloads/XXXX --header 'authorization: Bearer AAAXXXXXXXXXXXX'
You'll want to replace XXXX with the id value for your request. If you keep running this call, you'll see some of the values update. Once the download completes, it will look something like this:
{
"id": 7,
"results": [
"https://datafiniti-downloads.s3.amazonaws.com/15/7_1.txt?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20171116T174607Z&X-Amz-SignedHeaders=host&X-Amz-Expires=604800&X-Amz-Credential=AKIAJYCTIF46QVBTXWYA%2F2017xxxx%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Signature=ecf13f1bb4b7adfdde1a99143541afd1d12347292eb9ec3f6ed1316c64d4eekf"
],
"user_id": 15,
"status": "completed",
"date_started": "2017-11-16 17:46:06.0",
"date_updated": "2017-11-16 17:46:07.0",
"num_downloaded": 50,
"data_type": "product",
"query": "categories:shoes AND -categories:shirts AND categories:women AND (brand:* OR manufacturer:*) AND prices:*",
"format": "json",
"num_records": 50,
"total_cost": 50
}
Here's what these fields mean:
id | This is a unique identifier for the request. |
results | This is a list of links for all the result files generated for this data set. When you first issue the download request, it will be an empty list, but it will populate as the download progresses. |
user_id | This is an internal id for your user account. |
status | This indicates the status of your download. It will be set to completed once the download has finished. |
date_started | The date and time the download started. |
date_updated | The last time the download information was updated. |
num_downloaded | The number of records that have been downloaded so far. |
data_type | The data type you queried. |
query | The query you ran. |
format | The data format you requested. |
num_records | The total number of records that will be downloaded. |
total_cost | The number of credits this request has cost you. Product records only cost 1 credit per record. |
7. Download the result file(s)
Once the download response shows "status": "completed", you can download the data using the URLs in the results field.
If you've requested a lot of records (i.e., over 10,000), you may see more than 1 result object shown.
To download the result files, copy each url value and paste it into your browser. Your browser will initiate a download to your computer.
To download the result files, copy each url value run a command like:
curl 'https://datafiniti-downloads.s3.amazonaws.com/AAAXXXXXXXXXXXX/6073_1.txt?AWSAccessKeyId=AKIAIXQMCWHOZB3O35SA&Signature=2YtBsW9xY8CZrWDECcdLzyx4Jlk%3D&Expires=1484754763' > output.csv
You'll probably want to rename output.csv to something specific to this request.
8. Open the result file(s) in Excel
Navigate to the file you downloaded and open it.
The JSON data will actually be a text file, instead of a single JSON object. Each line in the text file is a JSON object. We format the data this way because most programming languages won't handle parsing the entire data set as a JSON object with their standard system calls very well.
From here, you'll most likely want to process the data using the programming language of your choice. Our other JSON guides provide instructions on how to process this data.
Updated about 1 year ago