Business Data With Python
For this guide, we're going to assume you're interested in using Datafiniti's business data to do some marketing analysis on hotels. Let's say you're a data scientist that's been tasked with the following:
- Collecting data on hotels in the US.
- Sort the business data by state.
- Find which states have the most hotels.
Your environment and data needs:
- You're working with Python.
- You want to work with CSV or JSON data.
Here are the steps we'll take:
Python Version
Note that we are using Python 3 for the examples below. Any 3.x version should work for this guide. You can always check your version via your python terminal via python --version.
1. Install the Requests Module for Python
In your terminal, run the following to install the requests module for Python:
pip3 install requests
2. Get Your API Token
The next thing you'll need is your API token. The API token lets you authenticate with Datafiniti API and tells it who you are, what you have access to, and so on. Without it, you can't use the API.
To get your API token, go the Datafiniti Web Portal (https://portal.datafiniti.co/settings/api), login, and click on your "Copy Token". Your API token will be a long string of letters and numbers. Store it somewhere you can easily reference.
API token reset
For security reasons, your API token will be automatically changed whenever you change your password.
Token Reference
For the rest of this document, we'll use AAAXXXXXXXXXXXX as a substitute example for your actual API token when showing example API calls.
3. Run Your First Search
The first thing we'll do is do write some code that will run a test search. This test search will give us a sense for what sort of data might be available. Eventually we'll refine our search so that we get back the most relevant data.
Since we want hotels, let's try a simple search that will just give us online listings for hotels.
Write the following code in your code editor (replace the dummy API token with your real API token):
# Illustrates an API call to Datafiniti's Business Database for hotels.
import requests
import urllib.parse
import json
# Set your API parameters here.
API_token = 'AAAXXXXXXXXXXXX'
#format = 'CSV'
format = 'JSON'
query = 'categories:hotels'
num_records = 1
download = False
request_headers = {
'Authorization': 'Bearer ' + API_token,
'Content-Type': 'application/json',
}
request_data = {
'query': query,
'view': view,
'format': format,
'num_records': num_records,
'download': download
}
# Make the API call.
r = requests.post('https://api.datafiniti.co/v4/businesses/search',json=request_data,headers=request_headers);
# Do something with the response.
if r.status_code == 200:
print(r.content)
else:
print('Request failed')
You should get a response similar to this:
{
"num_found": 139666,
"total_cost": 1,
"records": [
{
"address": "7030 Amin Dr",
"categories": [
"Hotels"
],
"city": "Chattanooga",
"country": "US",
"dateAdded": "2016-11-04T23:50:14Z",
"dateUpdated": "2016-11-04T23:50:14Z",
"descriptions": [
{
"dateSeen": [
"2016-11-09T19:26:53Z"
],
"sourceURLs": [
"http://www.hotels.com/ho141351/?locale=en_US&pos=HCOM_US"
],
"value": "No-frills hotel in Hamilton Place with health club"
}
],
"features": [
{
"key": "Services",
"value": [
"24-hour front desk, Dry cleaning/laundry service, Laundry facilities, Free newspapers in lobby"
]
},
{
"key": "Nearby Attractions",
"value": [
"[In Hamilton Place, Hamilton Place Mall (1.1 mi / 1.7 km), Dragon Dreams Museum (2.7 mi / 4.4 km), Tennessee Valley Railroad Museum (3.6 mi / 5.8 km), Concord Golf Club (3.8 mi / 6 km), Brown Acres Golf Course (4 mi / 6.5 km)]"
]
}
],
"imageURLs": [
"https://exp.cdn-hotels.com/hotels/1000000/120000/117400/117332/117332_95_n.jpg",
"https://exp.cdn-hotels.com/hotels/1000000/120000/117400/117332/117332_107_n.jpg"
],
"keys": [
"us/tn/chattanooga/7030amindr/1104338646"
],
"latitude": "35.04281",
"longitude": "-85.158",
"name": "Mainstay Suites Chattanooga",
"numRoom": 77,
"phones": [
"8004916126"
],
"postalCode": "37421",
"province": "TN",
"reviews": [
{
"date": "2013-11-11T00:00:00Z",
"dateAdded": "2016-11-04T23:50:14Z",
"dateSeen": [
"2016-11-06T00:00:00Z",
"2016-08-12T00:00:00Z"
],
"rating": 2,
"sourceURLs": [
"https://www.hotels.com/hotel/141351/reviews%20/"
],
"text": "Hotel was ok. Room not as up to date as I expected.",
"title": "Was ok",
"username": "A Traveler"
},
{
"date": "2014-11-03T00:00:00Z",
"dateAdded": "2016-11-04T23:50:14Z",
"dateSeen": [
"2016-08-09T00:00:00Z",
"2016-08-27T00:00:00Z",
"2016-07-18T00:00:00Z"
],
"rating": 3,
"sourceURLs": [
"https://www.hotels.com/hotel/141351/reviews%20/"
],
"text": "It was adequate for our one night stay there. Staff was very friendly and the room was clean but not very big. I would recommend to someone for a very short stay.",
"username": "scott"
}
],
"sourceURLs": [
"http://www.hotels.com/ho141351/?locale=en_US&pos=HCOM_US",
"https://www.hotels.com/hotel/141351/reviews%20/"
],
"id": "AVwcsllU_7pvs4fzx-yW"
}
]
Let's break down each of the parameters we sent in our request:
| API Call Component | Description |
|---|---|
"query": "categories:hotels" | query tells the API what you want to search. In this case, you're telling the API you want to search by categories. Any business that has hotels listed in its categories field will be returned. |
"num_records": 1 | num_records tells the API how many records to return in its response. In this case, you just want to see 1 matching record. |
"format":"xxxx" | "format" tells the API what format to output the data in the response. Can be either CSV or JSON. |
Now let's dive through the response the API returned:
| Response Field | Description |
|---|---|
"num_found" | The total number of available records in the database that match your query. If you end up downloading the entire data set, this is how many records you'll use. |
"total_cost" | The number of credits this request has cost you. Business records only cost 1 credit per record. |
"records" | The first available matches to your query. If there are no matches, this field will be empty. Within each record returned, you'll see multiple fields shown. This is the data for each record. |
Within the records field, you'll see a single business returned with multiple fields and the values associated with that business. The JSON response will show all fields that have a value. It won't show any fields that don't have a value.
Each business record will have multiple fields associated with it. You can see a full list of available fields in our Business Data Schema.
4. Refine Your Search
If you think about the original query we made, you'll realize we didn't really specify which geography we're interested in. Since we only want US hotels, we should narrow our search appropriately. Modify your code to look like this:
# Illustrates an API call to Datafiniti's Business Database for hotels.
import requests
import urllib.parse
import json
# Set your API parameters here.
API_token = 'AAAXXXXXXXXXXXX'
format = 'JSON'
query = 'categories:hotels AND country:US'
num_records = 10
download = False
request_headers = {
'Authorization': 'Bearer ' + API_token,
'Content-Type': 'application/json',
}
request_data = {
'query': query,
'view': view,
'format': format,
'num_records': num_records,
'download': download
}
# Make the API call.
r = requests.post('https://api.datafiniti.co/v4/businesses/search',json=request_data,headers=request_headers);
# Do something with the response.
if r.status_code == 200:
print(r.content)
else:
print('Request failed')
This query is different in a couple ways:
- It adds
AND country:USto narrow down results to just US hotels. - It changes
records=1torecords=10so we can look at more sample matches. - It changes
format='JSON'toformat='CSV'.
Datafiniti lets you construct very refined boolean queries. If you wanted to do more complicated searches, you could OR operations, negation, and more.
You can run the Python code above to see the difference in the results.
If you would like to narrow your search to just exact matches you can place the search term in quotation marks.
# Illustrates an API call to Datafiniti's Business Database for hotels.
import requests
import urllib.parse
import json
# Set your API parameters here.
API_token = 'AAAXXXXXXXXXXXX'
format = 'CSV'
query = 'name:"Datafiniti LLC"'
num_records = 10
download = False
request_headers = {
'Authorization': 'Bearer ' + API_token,
'Content-Type': 'application/json',
}
request_data = {
'query': query,
'view': view,
'format': format,
'num_records': num_records,
'download': download
}
# Make the API call.
r = requests.post('https://api.datafiniti.co/v4/businesses/search',json=request_data,headers=request_headers);
# Do something with the response.
if r.status_code == 200:
print(r.content)
else:
print('Request failed')
The above query will only return businesses with the name Datafiniti LLC.
5. Initiate a Download of the Data
Once we like what we see from the sample matches, it's time to download a larger data set! To do this, we're going to update our code a fair bit (an explanation follows):
# Illustrates an API call to Datafiniti's Product Database for hotels.
import requests
import urllib.parse
import json
import time
# Set your API parameters here.
API_token = 'AAAXXXXXXXX'
view = 'business_basic'
format = 'CSV'
query = 'categories:hotels AND country:US'
num_records = 50
download = True
request_headers = {
'Authorization': 'Bearer ' + API_token,
'Content-Type': 'application/json',
}
request_data = {
'query': query,
'num_records': num_records,
'view': view,
'format': format,
'num_records': num_records,
'download': download
}
# Make the API call.
r = requests.post('https://api.datafiniti.co/v4/businesses/search',json=request_data,headers=request_headers);
# Do something with the response.
if r.status_code == 202:
request_response = r.json()
print(request_response)
# Keep checking the request status until the download has completed
download_id = request_response['id']
download_status = request_response['status']
while (download_status != 'completed'):
time.sleep(5)
download_r = requests.get('https://api.datafiniti.co/v4/downloads/' + str(download_id),headers=request_headers);
download_response = download_r.json()
download_status = download_response['status']
print('Records downloaded: ' + str(download_response['num_downloaded']))
# Once the download has completed, get the list of links to the result files and download each file
if download_status == 'completed':
result_list = download_response['results']
i = 1;
for result in result_list:
filename = str(download_id) + '_' + str(i) + '.' + format
urllib.request.urlretrieve(result,filename)
print('File: ' + str(i) + ' out of ' + str(len(result_list)) + ' saved: ' + filename)
i += 1
else:
print('Request failed')
print(r)
A few things to pay attention to in the above code:
- We change
num_recordsfrom10to50. This will download the first 50 matching records. If we wanted to download all matching records, we would removenum_records. - We set the view to
business_basic. This will nest fields like categories and features into a single cell (instead splitting them across multiple rows and columns). - Change
download=falsetodownload=true.
Num_records
If num_records is not specified, ALL of the records matching the query will be downloaded.
Since we've handled multiple steps of the download process in this code, we won't go into the details here, but we do recommend you familiarize yourself with those steps. Checking them out in our Business Data with Postman and JSON guide will be helpful.
6. Checking Your Download Status
You will be presented with a response JSON different from the previous download being false. Whenever your download is true, Datafiniti will provide a download ID in the response file along with your credits used and a status. Below is an example of the response of your property search API. You can gather the following fields from the response JSON:
status- your status can be: completed, cancelled, queued, or runningnum_downloaded- you show the amount of records download so farproperty_cost- cost of credit for this download, will update once status = completedID- most important to track your download.
{
"status": "queued",
"num_downloaded": 0,
"num_records_suppressed": 0,
"people_cost": 0,
"property_cost": 0,
"product_cost": 0,
"business_cost": 0,
"total_cost": 0,
"fields": [
{
"name": "address"
},
{
"name": "apiURLs",
"flatten": false
},
{
"name": "careerPageURL"
},
{
"name": "categories",
"flatten": false
},
{
"name": "city"
},
{
"name": "claimed",
"flatten": false
},
{
"name": "country"
},
{
"name": "cuisines",
"flatten": false
},
{
"name": "dateAdded"
},
{
"name": "dateUpdated"
},
{
"name": "descriptions",
"flatten": false
},
{
"name": "domains",
"flatten": false
},
{
"name": "emails",
"flatten": false
},
{
"name": "facebookPageURL"
},
{
"name": "faxes",
"flatten": false
},
{
"name": "features",
"flatten": false
},
{
"name": "geoLocation"
},
{
"name": "hours",
"flatten": false
},
{
"name": "imageURLs",
"flatten": false
},
{
"name": "isClosed"
},
{
"name": "keys",
"flatten": false
},
{
"name": "languagesSpoken",
"flatten": false
},
{
"name": "latitude"
},
{
"name": "longitude"
},
{
"name": "menuPageURL"
},
{
"name": "menus",
"flatten": false
},
{
"name": "name"
},
{
"name": "neighborhoods",
"flatten": false
},
{
"name": "numEmployeesMin"
},
{
"name": "numEmployeesMax"
},
{
"name": "numRoom"
},
{
"name": "ownershipType"
},
{
"name": "paymentTypes",
"flatten": false
},
{
"name": "people",
"flatten": false
},
{
"name": "phones",
"flatten": false
},
{
"name": "postalCode"
},
{
"name": "priceRangeCurrency"
},
{
"name": "priceRangeMin"
},
{
"name": "priceRangeMax"
},
{
"name": "primaryCategories",
"flatten": false
},
{
"name": "productsOrServices",
"flatten": false
},
{
"name": "province"
},
{
"name": "revenueCurrency"
},
{
"name": "revenueMin"
},
{
"name": "revenueMax"
},
{
"name": "reviews",
"flatten": false
},
{
"name": "rooms",
"flatten": false
},
{
"name": "sic"
},
{
"name": "sourceURLs",
"flatten": false
},
{
"name": "stockSymbol"
},
{
"name": "technologiesUsed",
"flatten": false
},
{
"name": "twitter"
},
{
"name": "websites",
"flatten": false
},
{
"name": "yearIncorporated"
},
{
"name": "yearOpened"
}
],
"sort": true,
"auto_trace": false,
"only_traceable": false,
"format": "csv",
"suppressed_fields": [],
"enriched_fields": [],
"query": "categories:shoes AND -categories:shirts AND categories:women AND (brand:* OR manufacturer:*) AND prices:*",
"num_records": 50,
"data_type": "product",
"user": 126609,
"results": [],
"date_started": "2025-04-09T20:32:22.163Z",
"date_updated": "2025-04-09T20:32:22.163Z",
"_id": 847070,
"is_suppression_job": false,
"is_enrichment_job": false,
"id": "847070"
}
You can track the status of your download via the following method using our GET https://api.datafiniti.co/v4/downloads/:id endpoint
Track Your Download Via the API
The following code can be used to track your download ID:
import requests
url = "https://api.datafiniti.co/v4/downloads/811043?api_key=<your_API_key>"
headers = {
"Authorization": "Bearer <your_API_key>",
"accept": "application/json"
}
try:
response = requests.get(url, headers=headers, timeout=30)
response.raise_for_status() # Raise an exception for HTTP errors
print(response.text)
except requests.exceptions.RequestException as e:
print(f"Request Error: {e}")
The response of your code will provide you with the following JSON:
{
"status": "completed",
"num_downloaded": 50,
"num_records_suppressed": 0,
"people_cost": 0,
"property_cost": 0,
"product_cost": 0,
"business_cost": 50,
"total_cost": 50,
"sort": true,
"auto_trace": false,
"only_traceable": false,
"format": "csv",
"suppressed_fields": [],
"enriched_fields": [],
"_id": 710516,
"query": "categories:hotels AND country:US",
"num_records": 50,
"data_type": "business",
"user": 1226609,
"results": [
"https://datafiniti-downloads.s3.amazonaws.com/126609/811043_1.csv?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20250317T200355Z&X-Amz-SignedHeaders=host&X-Amz-Expires=604800&X-Amz-Credential=AKIAZSCI425AD5EKHVNH%2F20250317%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Signature=4c14da1d1df9eb490a0ab7c329b6f60f87c87edda2fe3b1a3dc857ea6e639sdfas6dc"
],
"date_started": "2025-03-17T20:00:46.733Z",
"date_updated": "2025-03-17T20:03:55.926Z",
"is_suppression_job": false,
"is_enrichment_job": false,
"id": "847070"
}
Track Your Download Via the Portal
You can track the status of your Datafiniti download via the portal in the download page here.
For more information please read our Downloading Result Files.
You can match the ID from your API response to the download ID on the page here:
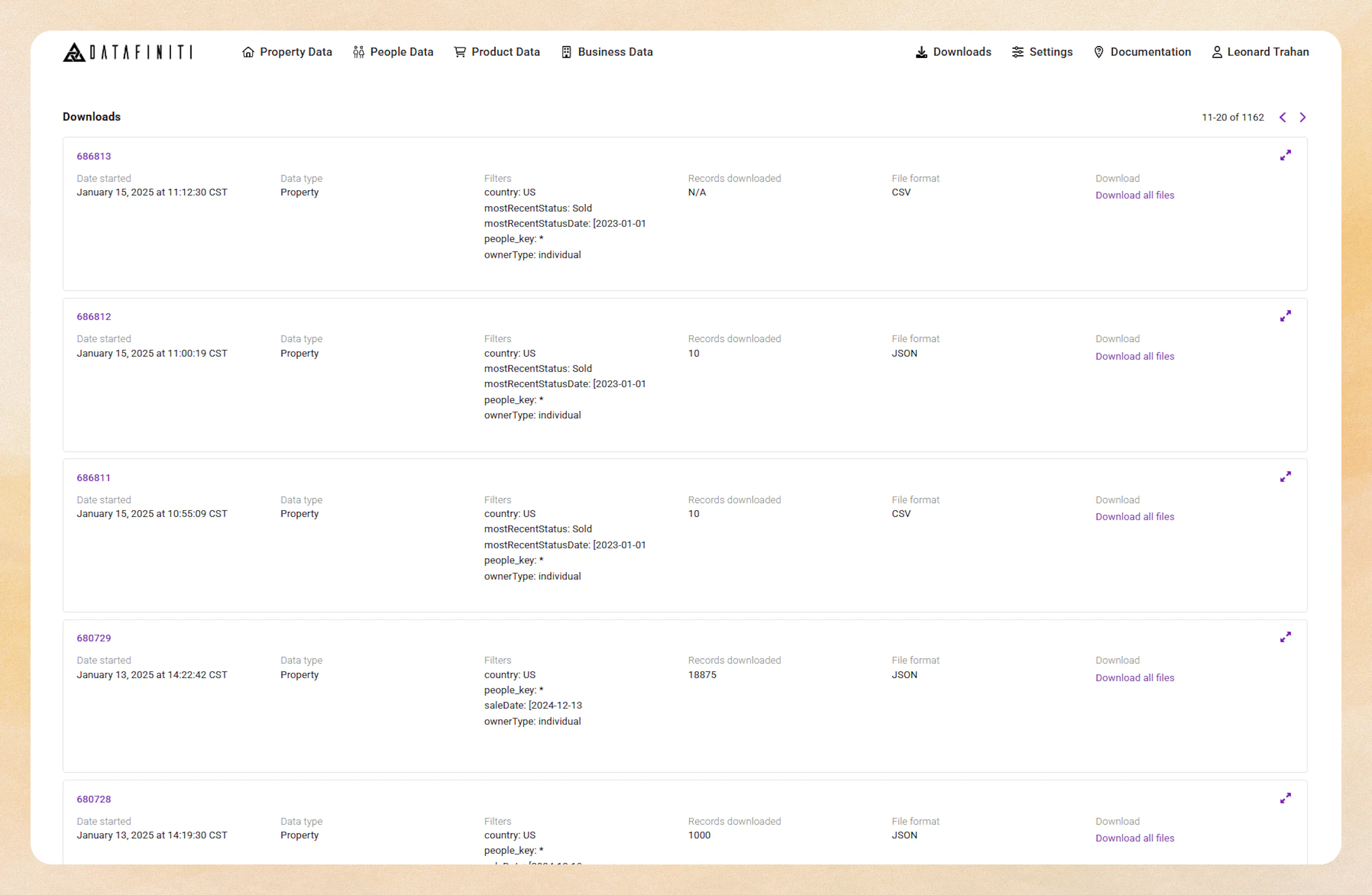
Track Via Our Reference Page
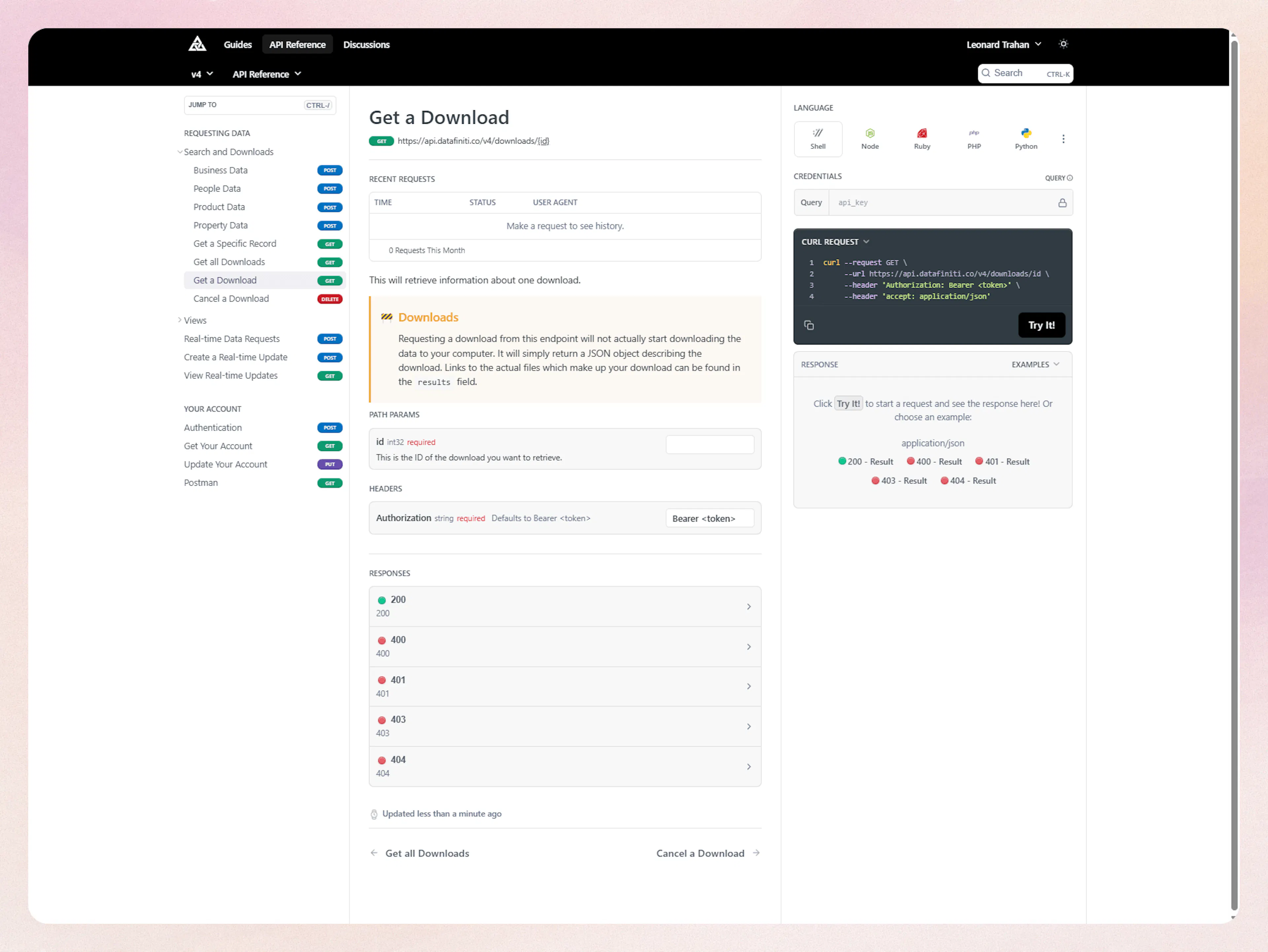
You can track the status of your Datafiniti download via the API reference page Get a Download. You can match the ID from your API response to the download ID on the page here:
7. Parse the JSON Data
Open the Result File(s) in Excel
The download code will save one or more result files to your project folder. Open one of those files in Excel. It will look something like:
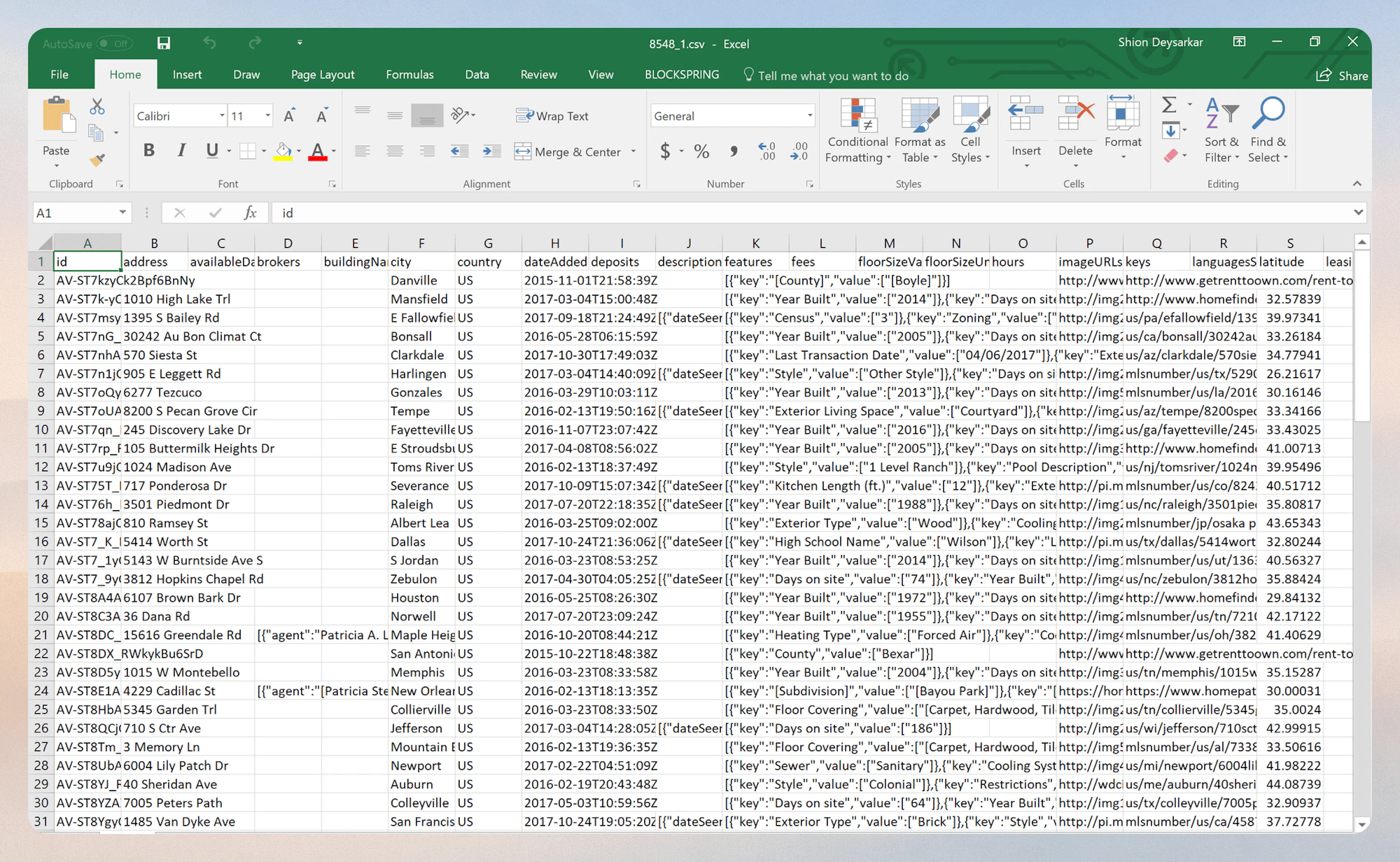
Parse the JSON Data
The download code will save one or more result files to your project folder.
JSON format
The JSON data will actually be a text file, instead of a single JSON object. Each line in the text file is a JSON object. We format the data this way because most programming languages won't handle parsing the entire data set as a JSON object with their standard system calls very well.
We'll need to parse the file into an array of JSON objects. We can use code similar to this to handle the parsing:
import json
# Set the location of your file here
filename = 'xxxx_x.txt'
records = []
with open(filename) as myFile:
for line in myFile:
records.append(json.loads(line))
for record in records:
# Edit these lines to do more with the data
print json.dumps(record, indent=4, sort_keys=True)
You can edit the code in the for loop above to do whatever you'd like with the data, such as store the data in a database, write it out to your console, etc.